
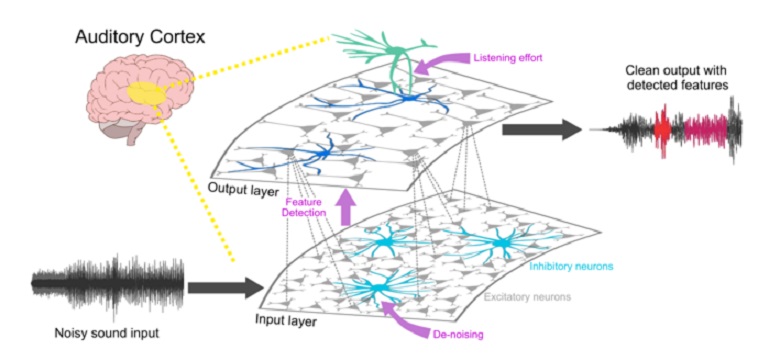
En un artículo publicado hoy en ‘Communications Biology’, neurocientíficos auditivos de la Universidad de Pittsburgh describen un modelo de aprendizaje automático que ayuda a explicar cómo el cerebro reconoce el significado de los sonidos de comunicación, como llamadas de animales o palabras habladas.
El algoritmo descrito en el estudio modela cómo los animales sociales, incluidos los monos tití y los conejillos de indias, usan redes de procesamiento de sonidos en su cerebro para distinguir entre categorías de sonido, como llamadas de apareamiento, comida o peligro, y actuar en consecuencia.
El estudio es un paso importante hacia la comprensión de las complejidades del procesamiento neuronal que subyace al reconocimiento de sonido. Los conocimientos de este trabajo allanan el camino para comprender y, eventualmente, tratar los trastornos que afectan el reconocimiento del habla y mejorar los audífonos.
“Más o menos todos los que conocemos perderán parte de su audición en algún momento de sus vidas, ya sea como resultado del envejecimiento o la exposición al ruido. Comprender la biología del reconocimiento de sonido y encontrar formas de mejorarlo es importante”, dijo el autor principal y profesor asistente de neurobiología de Pitt, Srivatsun Sadagopan. “Pero el proceso de comunicación vocal es fascinante en sí mismo. La forma en que nuestros cerebros interactúan entre sí y pueden tomar ideas y transmitirlas a través del sonido es mágica”.
Variedad de sonidos
Los seres humanos y los animales se encuentran con una asombrosa diversidad de sonidos todos los días, desde la cacofonía de la jungla hasta el zumbido dentro de un restaurante concurrido. Independientemente de la contaminación acústica del mundo que nos rodea, los humanos y otros animales pueden comunicarse y entenderse entre sí, incluido el tono de voz o el acento. Cuando escuchamos la palabra «hola», por ejemplo, reconocemos su significado independientemente de si se dijo con acento estadounidense o británico, si el orador es una mujer o un hombre, o si estamos en una habitación tranquila o muy ocupados.
El equipo comenzó con la intuición de que la forma en que el cerebro humano reconoce y capta el significado de los sonidos de comunicación puede ser similar a la forma en que reconoce caras en comparación con otros objetos. Los rostros son muy diversos pero tienen algunas características comunes.
En lugar de hacer coincidir cada rostro que encontramos con un rostro “plantilla” perfecto, nuestro cerebro detecta características útiles, como los ojos, la nariz y la boca, y sus posiciones relativas, y crea un mapa mental de estas pequeñas características que definen un rostro.
Modelo de aprendizaje automático
En una serie de estudios, el equipo demostró que los sonidos de comunicación también pueden estar compuestos por características tan pequeñas. Los investigadores primero construyeron un modelo de aprendizaje automático de procesamiento de sonido para reconocer los diferentes sonidos emitidos por animales sociales. Para probar si las respuestas cerebrales se correspondían con el modelo, registraron la actividad cerebral de los conejillos de indias que escuchaban los sonidos de comunicación de sus parientes.
Las neuronas en las regiones del cerebro que son responsables de procesar los sonidos se iluminaron con una ráfaga de actividad eléctrica cuando escucharon un ruido que tenía características presentes en tipos específicos de estos sonidos, similar al modelo de aprendizaje automático.
Luego querían comparar el rendimiento del modelo con el comportamiento real de los animales.
Los conejillos de indias se colocaron en un recinto y se expusieron a diferentes categorías de sonidos: chirridos y gruñidos que se clasifican como señales de sonido distintas. Luego, los investigadores entrenaron a los conejillos de indias para que caminaran por diferentes rincones del recinto y recibieran recompensas de frutas según la categoría de sonido que se reprodujera.
Luego, hicieron las tareas más difíciles: para imitar la forma en que los humanos reconocen el significado de las palabras pronunciadas por personas con diferentes acentos, los investigadores ejecutaron llamadas de conejillos de Indias a través de un software que altera el sonido, acelerándolos o ralentizándolos, subiendo o bajando su tono, o agregando ruido y ecos.
Los animales no solo pudieron realizar la tarea de manera tan constante como si las llamadas que escucharon no se alteraran, sino que continuaron desempeñándose bien a pesar de los ecos o ruidos artificiales. Mejor aún, el modelo de aprendizaje automático describió perfectamente su comportamiento (y la activación subyacente de las neuronas de procesamiento de sonido en el cerebro).
Trasladar el modelo al habla humana
Como próximo paso, los investigadores están traduciendo la precisión del modelo de los animales al habla humana.
“Desde el punto de vista de la ingeniería, existen modelos de reconocimiento de voz mucho mejores. Lo que es único de nuestro modelo es que tenemos una estrecha correspondencia con el comportamiento y la actividad cerebral, lo que nos brinda una mayor comprensión de la biología. En el futuro, estos conocimientos se pueden utilizar para ayudar a las personas con afecciones del desarrollo neurológico o para ayudar a diseñar mejores audífonos”, dijo el autor principal Satyabrata Parida, Ph.D., becario postdoctoral en el departamento de neurobiología de Pitt .
“Muchas personas luchan con condiciones que les dificultan reconocer el habla”, dijo Manaswini Kar, estudiante en el laboratorio de Sadagopan. «Comprender cómo un cerebro neurotípico reconoce las palabras y da sentido al mundo auditivo que lo rodea hará posible comprender y ayudar a quienes luchan». Otro autor del estudio es Shi Tong Liu, Ph.D., de Pitt.










Recordamos que SALUD A DIARIO es un medio de comunicación que difunde información de carácter general relacionada con distintos ámbitos sociosanitarios, por lo que NO RESPONDEMOS a consultas concretas sobre casos médicos o asistenciales particulares. Las noticias que publicamos no sustituyen a la información, el diagnóstico y/o tratamiento o a las recomendaciones QUE DEBE FACILITAR UN PROFESIONAL SANITARIO ante una situación asistencial determinada.
SALUD A DIARIO se reserva el derecho de no publicar o de suprimir todos aquellos comentarios contrarios a las leyes españolas o que resulten injuriantes, así como los que vulneren el respeto a la dignidad de la persona o sean discriminatorios. No se publicarán datos de contacto privados ni serán aprobados comentarios que contengan 'spam', mensajes publicitarios o enlaces incluidos por el autor con intención comercial.
En cualquier caso, SALUD A DIARIO no se hace responsable de las opiniones vertidas por los usuarios a través de los canales de participación establecidos, y se reserva el derecho de eliminar sin previo aviso cualquier contenido generado en los espacios de participación que considere fuera de tema o inapropiados para su publicación.
* Campos obligatorios